['0+none.png', 'animal-class.png', 'arithmetic+operators.png', 'assignment+operators.png', 'book.txt', 'break+continue+pass.png', 'bug.png', 'car-class.png', 'class+method.png', 'class+mixin.png', 'class-properties.png', 'comparison+operators.png', 'containment.png', 'converting+between+data+types.png', 'data-types.png', 'datetime.png', 'decorator.png', 'dictionary-comprehension.png', 'dictionary-items.png', 'dictionary.png', 'errors.txt', 'f-string.png', 'file-open-modes.png', 'flask+about-1.png', 'flask+hello-world+tags.png', 'flask+hello-world.png', 'flask+home-1.png', 'flask-for+loop.png', 'flask-form-after.png', 'flask-form-before.png', 'flask-usage.png', 'for+loop.png', 'fourlines.txt', 'frameworks+modules+libraries.png', 'function+call.png', 'function+parameter+return.png', 'function.png', 'gulliver.txt', 'ide.png', 'if+elif+else.png', 'if+else.png', 'import.png', 'indentation.png', 'input+output.png', 'input-from-user.png', 'is+is-not.png', 'list-comprehension.png', 'list-indexing.png', 'list-slicing.png', 'logical+operators.png', 'naming-convention.png', 'nested+if+indentation.png', 'nested-data-structure.png', 'nested-loops.png', 'newfile.txt', 'nonetype.png', 'os-path.png', 'os.png', 'print+hello-world.png', 'random.png', 'read-file.png', 'read-web.png', 'reserved-keywords.png', 'runtime-errors.png', 'scope-keywords.png', 'scope.png', 'set.png', 'splat+args+kwargs.png', 'sqlite+chinook-closed.png', 'sqlite+chinook-open-db.png', 'sqlite+chinook-opened.png', 'sqlite+chinook-schema.png', 'sqlite+chinook-tables.png', 'sqlite+chinook-terminal.png', 'sqlite+path.png', 'string.png', 'subclass+inheritance.png', 'syntax-error.png', 'sys-files.png', 'system-exit.png', 'template.html', 'ternary+operator.png', 'try+except+else+finally.png', 'try+except.png', 'tuple.png', 'varable+assignment.png', 'web-server.png', 'while+loop.png']
 If using a keyword in a name cannot be avoided, then you can append a single trailing underscore. However, it is better to find a synonym for the keyword and use that instead.
If using a keyword in a name cannot be avoided, then you can append a single trailing underscore. However, it is better to find a synonym for the keyword and use that instead.
 The (recommended) maximum line length is 79 characters. This means that a line of code may have to be wrapped onto a continuation line. The continuation line indent cannot match the block indentation; otherwise, there will be an error. You can either add four further spaces to the continuation line indent or align with the opening delimiter on the preceding line.
The (recommended) maximum line length is 79 characters. This means that a line of code may have to be wrapped onto a continuation line. The continuation line indent cannot match the block indentation; otherwise, there will be an error. You can either add four further spaces to the continuation line indent or align with the opening delimiter on the preceding line. Often when editing your code, you would like to stop the program at a specific point to see what state it is in at that time. Python gives an option of
Often when editing your code, you would like to stop the program at a specific point to see what state it is in at that time. Python gives an option of  When learning Python, the most commonly seen error messages are syntax errors. These are also called parsing errors. The parser repeats the line where the error has been detected in the terminal. A caret
When learning Python, the most commonly seen error messages are syntax errors. These are also called parsing errors. The parser repeats the line where the error has been detected in the terminal. A caret  Logic errors are when the code gives a different output than you were expecting. These are the most difficult errors to fix. A computer does exactly what it is programmed to do. Therefore a logic error is a mistake or misunderstanding from the developer. If the syntax of the code is correct, then there will be no error posted in the terminal.
Logic errors are when the code gives a different output than you were expecting. These are the most difficult errors to fix. A computer does exactly what it is programmed to do. Therefore a logic error is a mistake or misunderstanding from the developer. If the syntax of the code is correct, then there will be no error posted in the terminal.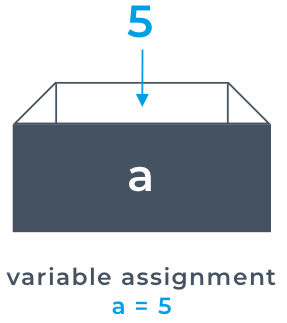 Fortunately, computers are much more than just fancy calculators. Computers have a hardware component called RAM (Random Access Memory). RAM is a storage medium for computers. Unlike a hard drive, RAM is volatile, so any data stored in RAM will be lost after the computer has been shut down. RAM is used to store any data that is used by a computer program when it is running (also known as “being executed”). Not only do variables allow us to persist data that we may need for our program in memory, but it also allows us to provide meaningful names for the data that we’re storing. A variable acts as a placeholder in memory for a piece of data. The value of the data is stored in that placeholder. We can then use the name of that variable as a reference to that location in memory.
Fortunately, computers are much more than just fancy calculators. Computers have a hardware component called RAM (Random Access Memory). RAM is a storage medium for computers. Unlike a hard drive, RAM is volatile, so any data stored in RAM will be lost after the computer has been shut down. RAM is used to store any data that is used by a computer program when it is running (also known as “being executed”). Not only do variables allow us to persist data that we may need for our program in memory, but it also allows us to provide meaningful names for the data that we’re storing. A variable acts as a placeholder in memory for a piece of data. The value of the data is stored in that placeholder. We can then use the name of that variable as a reference to that location in memory. Python is quite forgiving when it comes to naming. However, there are suggested style rules that you should follow. Variable names should be lowercase. However Python will still work if you use capital letters in your variables. Variable names are case sensitive so take care not to write
Python is quite forgiving when it comes to naming. However, there are suggested style rules that you should follow. Variable names should be lowercase. However Python will still work if you use capital letters in your variables. Variable names are case sensitive so take care not to write 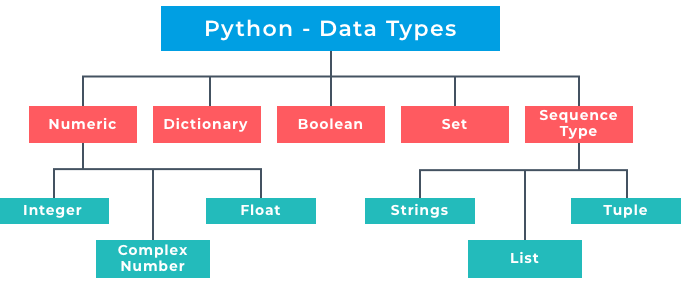 Python stores data in different types. A data type is an essential concept as different types can do different things. Perhaps the most basic data type in computing is boolean (
Python stores data in different types. A data type is an essential concept as different types can do different things. Perhaps the most basic data type in computing is boolean (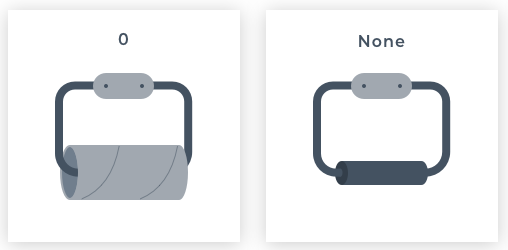
 We now know how to create different types of variables using numbers, but we can store string literals too. We do this in the same way that we create a variable with a number. In Python, anything contained inside quotation marks is treated as a string. We can use double quotes
We now know how to create different types of variables using numbers, but we can store string literals too. We do this in the same way that we create a variable with a number. In Python, anything contained inside quotation marks is treated as a string. We can use double quotes  Python provides us with built-in functions to convert from one data type to another. For example,
Python provides us with built-in functions to convert from one data type to another. For example, 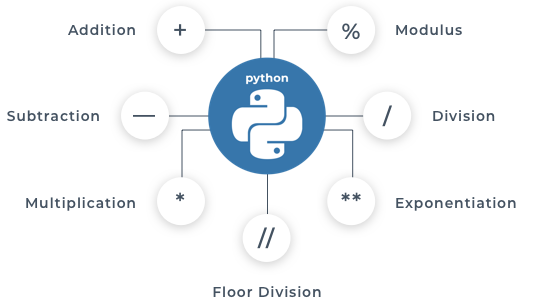 Operators perform operations on operands. For example,
Operators perform operations on operands. For example, 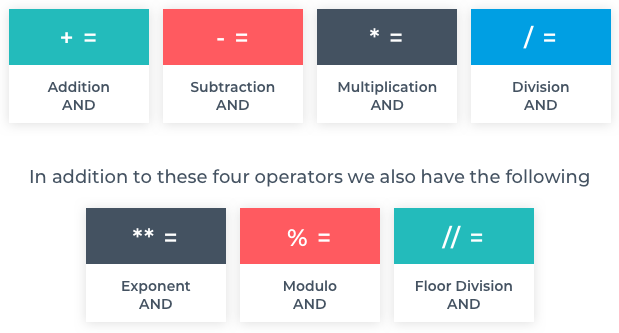
 In coding, we often want to compare values. The most straightforward comparison is equality. In Python, as we have used
In coding, we often want to compare values. The most straightforward comparison is equality. In Python, as we have used 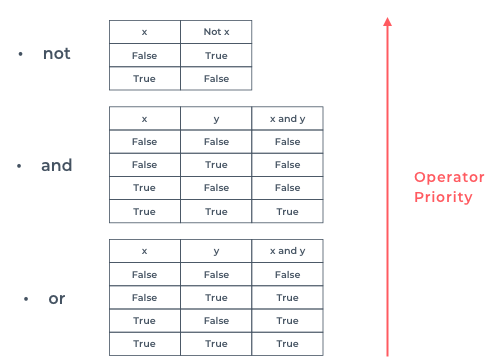 For the
For the  So far we have been checking if something is of equal value, type or
So far we have been checking if something is of equal value, type or  In coding, it is often useful to check whether a value exists within a sequence. The sequence can be a list or a range or a string. Just like in Javascript when you used the
In coding, it is often useful to check whether a value exists within a sequence. The sequence can be a list or a range or a string. Just like in Javascript when you used the  The simplest way to use python is to type a single command or line of code into the python interactive shell. For example, if you type
The simplest way to use python is to type a single command or line of code into the python interactive shell. For example, if you type  The more advanced form of doing string formatting is by using what are called; f-strings.
The more advanced form of doing string formatting is by using what are called; f-strings.
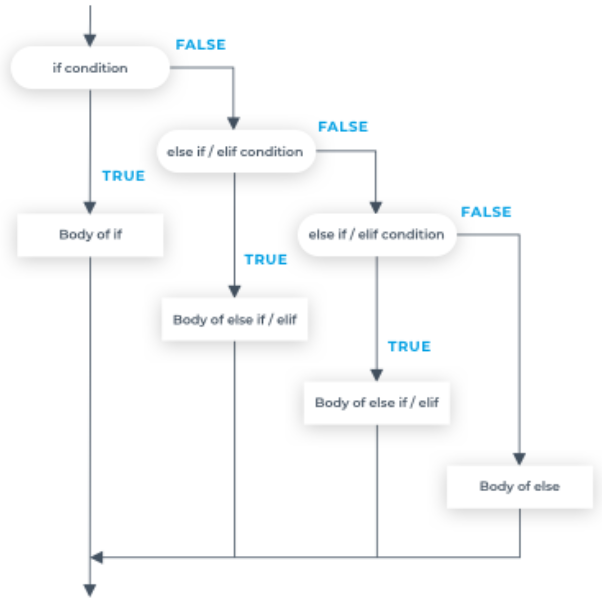
 In addition to using the
In addition to using the 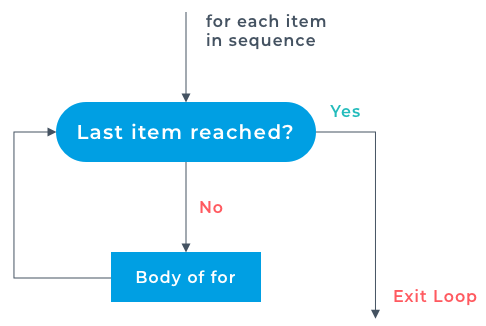
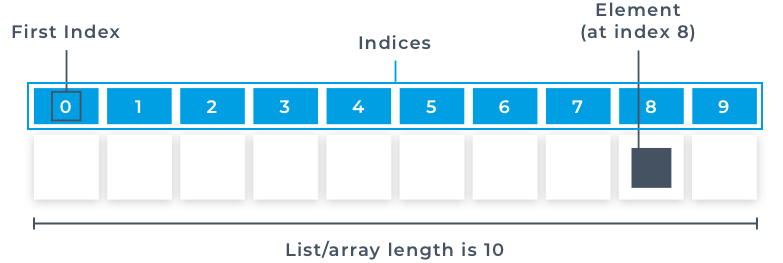 When coding, you would choose a
When coding, you would choose a 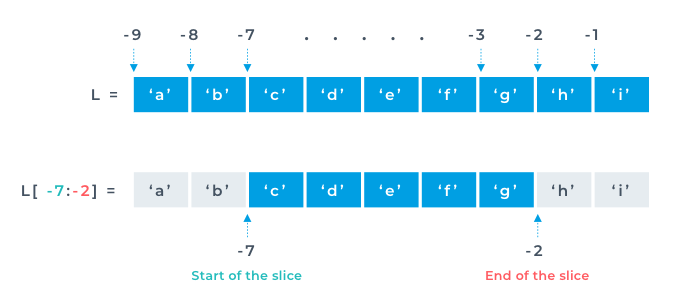 Indexing was only limited to accessing a single element, Slicing on the other hand is accessing a sequence of data inside the list. In other words "slicing" the list. Slice notation with indexing is used to slice the list up. We can slice up lists to get subsets of a list. For example, if we wanted to get the first two items in a list, then we would use the following syntax
Indexing was only limited to accessing a single element, Slicing on the other hand is accessing a sequence of data inside the list. In other words "slicing" the list. Slice notation with indexing is used to slice the list up. We can slice up lists to get subsets of a list. For example, if we wanted to get the first two items in a list, then we would use the following syntax 
 This is called nesting.
This is called nesting. Tuples are similar to lists but only big difference is the elements in a tuple cannot be changed. Tuples are the natural extension of ordered pairs, triplets etc in mathematics.
Tuples are similar to lists but only big difference is the elements in a tuple cannot be changed. Tuples are the natural extension of ordered pairs, triplets etc in mathematics.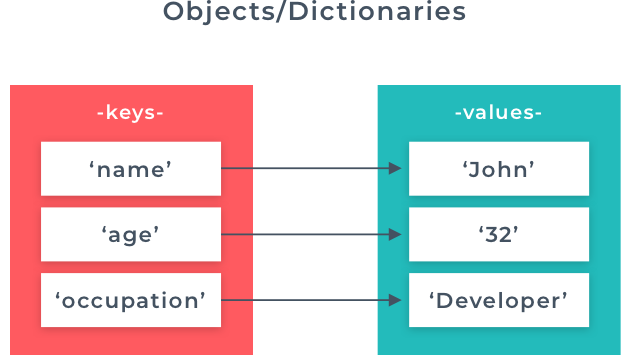 Dictionaries allow us to take things a step further when it comes to storing information in a collection. Dictionaries will enable us to use what are called key/value pairs. In the example above, 'immutable' is the key, and its derivation is the value. When using a dictionary in Python, we define our key/value pairs enclosed in curly braces
Dictionaries allow us to take things a step further when it comes to storing information in a collection. Dictionaries will enable us to use what are called key/value pairs. In the example above, 'immutable' is the key, and its derivation is the value. When using a dictionary in Python, we define our key/value pairs enclosed in curly braces 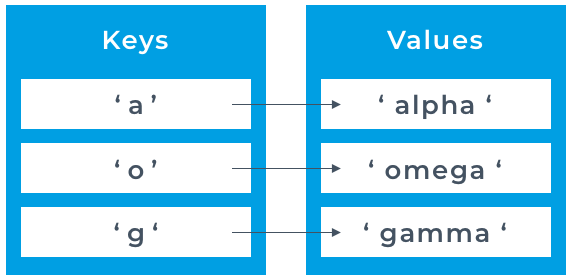 This time in the runnable example, we have created our dictionary with default values of empty strings. In this case, we have used the
This time in the runnable example, we have created our dictionary with default values of empty strings. In this case, we have used the  The difference in the syntax is that curly rather than square brackets are used. Also, before the for keyword you need to include the key and value separated with a colon.
The difference in the syntax is that curly rather than square brackets are used. Also, before the for keyword you need to include the key and value separated with a colon. It also uses curly brackets, but commas separate items in the collection. However, this means that to create an empty set; you have to use the method
It also uses curly brackets, but commas separate items in the collection. However, this means that to create an empty set; you have to use the method 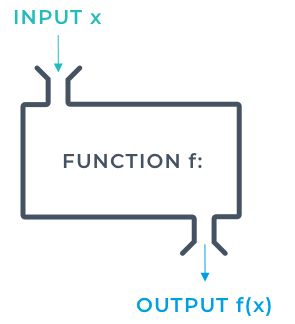 Up until now we’ve been writing little pieces of code and haven’t been concerned about the structure or readability of our application. What I mean by this is that all the code we’ve written so far has been at the top level of our Python files. There once was a time when applications were written in this fashion, but the sheer amount of what makes up the basis of an application would become unwieldy very quickly. Thankfully there are specific constructs that we can use to help improve this. Functions allow us to write a chunk of code that we can invoke whenever we choose.
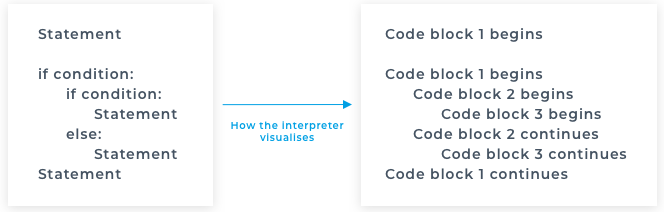
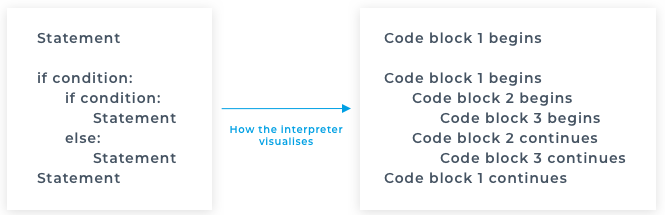
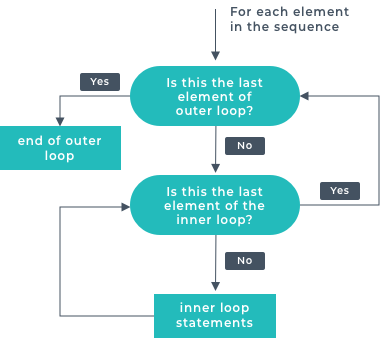
Up until now we’ve been writing little pieces of code and haven’t been concerned about the structure or readability of our application. What I mean by this is that all the code we’ve written so far has been at the top level of our Python files. There once was a time when applications were written in this fashion, but the sheer amount of what makes up the basis of an application would become unwieldy very quickly. Thankfully there are specific constructs that we can use to help improve this. Functions allow us to write a chunk of code that we can invoke whenever we choose. In the image the code runs in this order
In the image the code runs in this order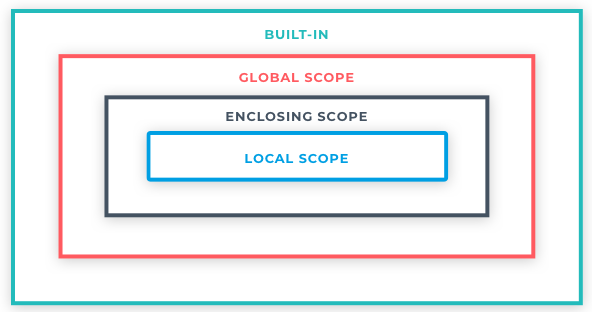
 Python deals regards variables as local, if not otherwise declared. This will cause problems, for example, if you access a variable declared outside a function (global) within a function and try and reassign its value. If you then access the global variable outside the function, it will still have its original value rather than the new one reassigned within the function. One workaround would be to return the variable from the function so now it's reassigned value is available outside the function. However, there is a better option, and that is to use keywords to state which scope is to be used unambiguously.
Python deals regards variables as local, if not otherwise declared. This will cause problems, for example, if you access a variable declared outside a function (global) within a function and try and reassign its value. If you then access the global variable outside the function, it will still have its original value rather than the new one reassigned within the function. One workaround would be to return the variable from the function so now it's reassigned value is available outside the function. However, there is a better option, and that is to use keywords to state which scope is to be used unambiguously.
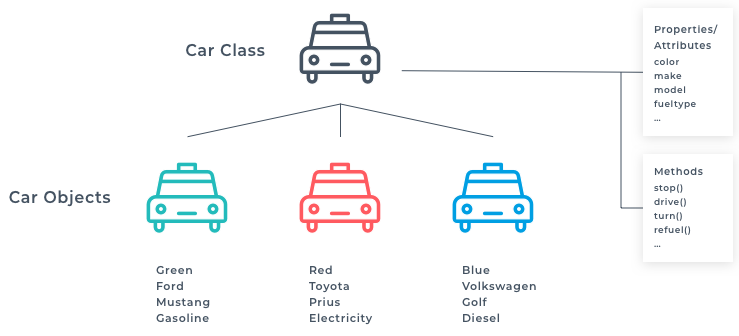
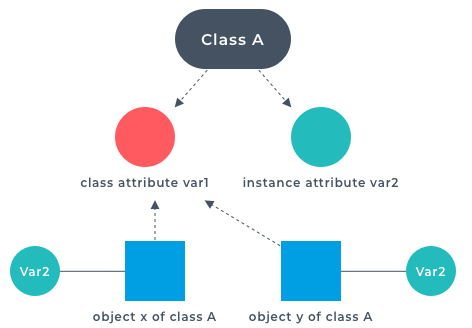

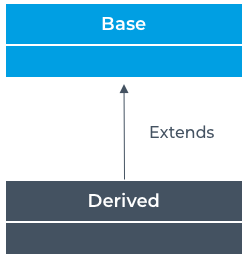
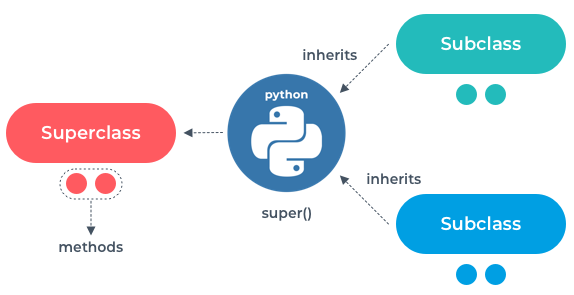 The purpose of a mixin is to reduce the amount of unnecessary duplication of code. If you have a piece of logic that is frequently repeated in the subclasses, then move it to a mixin.
The purpose of a mixin is to reduce the amount of unnecessary duplication of code. If you have a piece of logic that is frequently repeated in the subclasses, then move it to a mixin.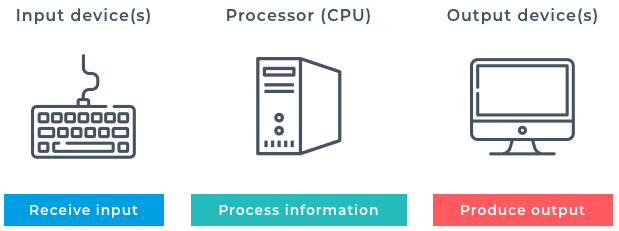 Most programs store data in memory while they're running. Choosing the correct data structure can make all the difference in the performance of an application. A skilled developer knows how to use and combine smaller data structures into more substantial and more elaborate models in memory. But as great as these models are, anything held in RAM, or Random Access Memory, is volatile. That means that when the program shuts down, either by deliberately exiting or as a result of a crash, then the data is lost.
Most programs store data in memory while they're running. Choosing the correct data structure can make all the difference in the performance of an application. A skilled developer knows how to use and combine smaller data structures into more substantial and more elaborate models in memory. But as great as these models are, anything held in RAM, or Random Access Memory, is volatile. That means that when the program shuts down, either by deliberately exiting or as a result of a crash, then the data is lost.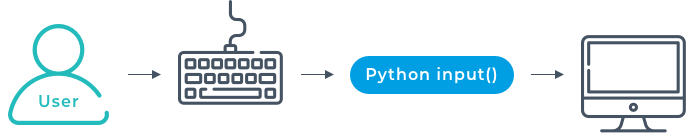 With that in mind, let’s take a look at how we can receive some input from a user. For this, we’ll need to use the input function. The input function takes a string as an argument. This is the prompt the user will see. The input function stops the running of the program and waits for the user to enter data in the command line and press return. Whatever the user inputs is converted to a string. Therefore if you need it as a number, you need to convert it.
With that in mind, let’s take a look at how we can receive some input from a user. For this, we’ll need to use the input function. The input function takes a string as an argument. This is the prompt the user will see. The input function stops the running of the program and waits for the user to enter data in the command line and press return. Whatever the user inputs is converted to a string. Therefore if you need it as a number, you need to convert it. The most uncomplicated persistent storage is a text file. You can save lines of text in the file then use python
The most uncomplicated persistent storage is a text file. You can save lines of text in the file then use python 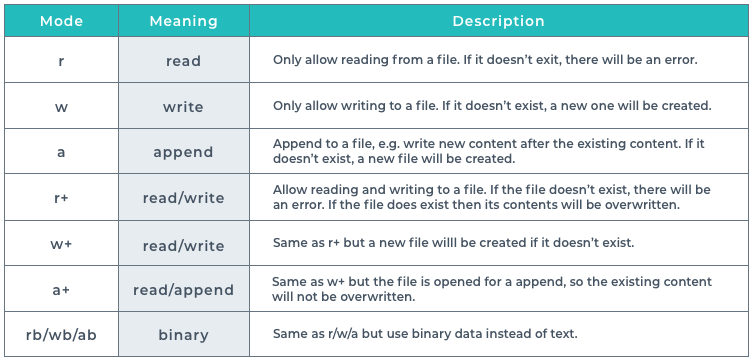

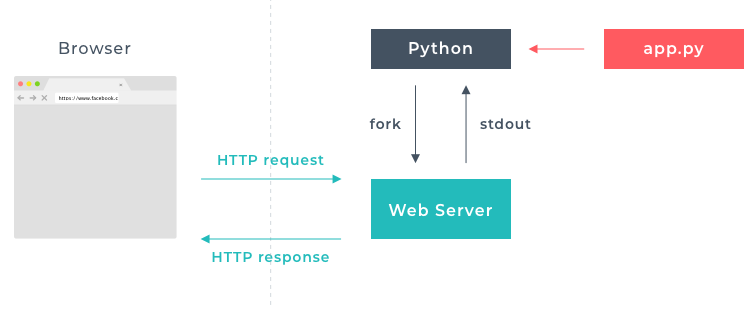 A web server hosts the files required for your website. It can read data from the browser and write data to the browser using HTTP protocols. You can also manipulate the data in your web server. A common use case would be to generate HTML files from a base template to reduce duplicate code.
A web server hosts the files required for your website. It can read data from the browser and write data to the browser using HTTP protocols. You can also manipulate the data in your web server. A common use case would be to generate HTML files from a base template to reduce duplicate code.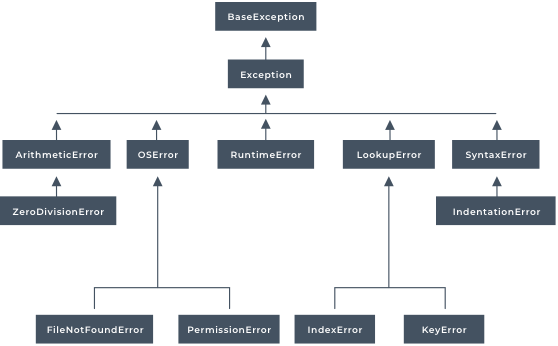
 In summary, the
In summary, the  The code placed in the
The code placed in the 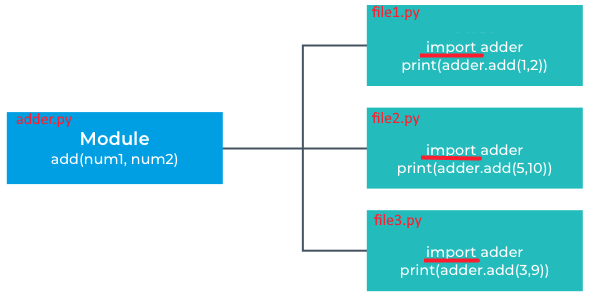
 A frequent use for this would be accessing the environment variables. Every computer has a set of environment variables listing information on how the machine is set up. Examples of this would be the directory structure of the home directory or the computers users profile.
A frequent use for this would be accessing the environment variables. Every computer has a set of environment variables listing information on how the machine is set up. Examples of this would be the directory structure of the home directory or the computers users profile.
 In the image, you can see file objects in the
In the image, you can see file objects in the 




