Software Engineering Practices
When you're working in industry, your code could potentially be used in production.
Production code just means code that is run on production servers. For example, when you're on your laptop using software products like Google, Amazon, the code that's running the service you're using is production code. Ideally, code that's being used in production should meet a number of criteria to ensure reliability and efficiency before it becomes public.
For one, the code needs to be clean.
Code is clean when it's readable, simple and concise. Writing clean code is very important in an industry setting where on a team that's constantly iterating over its work. This makes it much easier for yourself and others to understand and reuse your code.
In addition to being clean, your code should be modular. Meaning, your program is logically broken up into functions and modules. In programming, a module is just a file. Similarly to how you can encapsulate code in a function and reuse it by calling the function in different places, you can encapsulate code within a module or file and reuse it by importing it into other files.
Splitting a code into logical functions and modules, allows you to quickly find relevant pieces of code. You can often generalize these pieces of code to be reused in different places, to prevent yourself from writing extra unnecessary lines of code. Abstracting out these details into these functions and modules can really help in improving the readability of your code. Again, programming in a way that makes it easier for a team to understand and iterate on is crucial for production.
When you first sit down to start writing code for a new idea or task, it's easy to focus more on just getting it to work and pay little attention to writing good code. So, your code typically gets a little messy and repetitive at this stage of development. This is okay.
It's hard to know what's the best way to write your code before it's finished. For example, it could be difficult to know exactly what functions would best modularize the steps in your code if you haven't experimented enough with your code to understand what these steps are.
That's why you should always go back to do some refactoring after you've achieved a working model. Code refactoring is a term for restructuring your code to improve its internal structure without changing its external functionality.
Refactoring gives you an opportunity to clean and modularize your code after you've produced code that works. In the short-term, you might see this as a waste of time, since you could be moving on to the next feature. However, allocating time to refactoring your code really speeds up the time it will take you and your team to develop code in the long run. Refactoring your code consistently not only makes it much easier to come back to it later, it also allows you to reuse parts for different tasks and learn strong programming techniques along the way. The more you practice refactoring your code, the more intuitive it becomes.
The first tip for writing clean code, is to use meaningful descriptive names for your variables and functions. This can help you explain most of your code without comments.
Take a look at this code that initializes a list of student test scores, prints the mean, curves each score by multiplying its square root by 10, and then prints the mean of the new curved scores.
s = [88, 92, 79, 93, 85] # student test scores
print(sum(s) / len(s)) # print mean of test scores
s1 = [x ** 0.5 * 10 for x in s]
# curve score with square root method and store in new list
print(sum(s1) / len(s1)) # print mean of curved test scores
With this code, you wouldn't know what was happening right away without these comments. See how this compares to this cleaner code, which conveys the same purpose without the comments.
import numpy as np
import math
test_scores = [88, 92, 79, 93, 85]
print(np.mean(test_scores))
curved_test_scores = [math.sqrt(score) * 10 for score in test_scores]
print(np.mean(curved_test_scores))
Now, we know what both of these lists stand for without the comments, which will help us throughout the program wherever these variables are used. We also use the function with a descriptive name, mean, instead of running a calculation each time. This not only helps readability, but follows the DRY principle or don't repeat yourself that is important to writing modular code. In addition, we imported the math module to use its square root method instead of raising each score to 0.5 with double asterisks, which isn't only more readable, but also faster in Python 3.
Coming up with meaningful names often requires effort to get right. Here are some guidelines.
Be descriptive, and when appropriate, try implying the type of whatever you're naming.
age_list = [47, 12, 28, 52, 35]
for i, age in enumerate(age_list):
if age < 18:
is_minor = True
age_list[i] = "minor"
Notice we call this list, age_list instead of ages, which helps us avoid confusing the integer age and the list of ages later in this code.
For Booleans, it's often helpful to prefix the name with words like is_ or has_ to make it clear that it's a condition. You can also use parts of speech to imply types by starting function names with verbs and using nouns for variables. Normally, you don't want to use abbreviations unless the word will be used many, many times, and you especially don't want single letter names. However, exceptions include names for counters such as i in this example, as well as common variable names using math like, x, y, t, and so on.
Choosing when these exceptions can be made can be determined based on your audience for the code. If you work with data scientists, certain variables may be common knowledge. While if you work with full-stack engineers, it might be necessary to provide more descriptive names in these cases as well.
However, long names do not always mean meaningful names. You should be descriptive, but not with more characters than necessary.
def count_unique_values_of_names_list_with_set(names_list):
return len(set(names_list))
This example is very verbose. This function computes the number of unique values in a list regardless of what that list is. So, we can generalize and remove names_list from the function name, and replace the argument name with arr, which is standard to represent an arbitrary array. In addition, implementation details are unnecessary to include in a function name. So, we can remove with_set from the function name as well.
The resulting function is much more clean and concise while still being descriptive.
def count_unique_values(arr):
return len(set(arr))
Try testing how effective your names are by asking a fellow programmer to guess the purpose of a function or variable based on its name, without looking at your code. Coming up with meaningful names often requires effort to get right.
Use whitespace properly.
For more guidelines, check out the code layout section of PEP 8.
Writing Modular Code is a necessary practice in software development, where you split your program into logical functions and modules.
In general, it's always a good idea to follow the concept of DRY: Don't Repeat Yourself. Keep your code DRY - this means that any time you find yourself copying and pasting the same code a lot, it's probably an indication that there's a more efficient way to write it. You might be able to create a function, a class, shorten the code or eliminate it entirely by rewriting it in a different way.
Let's go back to the example earlier on grading test scores.
s = [88, 92, 79, 93, 85]
print(sum(test_scores) / len(test_scores))
s1 = []
for x in s :
s1.append(x + 5)
print(sum(curved_5) / len(curved_5))
s2 = []
for x in s:
s2.append(x + 10)
print(sum(s2) / len(s2))
s3 = []
for x in s:
s3.append(x ** 0.5 * 10)
print(sum(s3) / len(s3))
Here, we have a list of test scores that we curve in three different ways, say you're an educator who gave out a test that was too difficult or gave a question that was a little unfair. So, you decide to figure out a way to boost your students' scores.
For the first two methods, we add a flat curve of 5 points to each score and 10 points to each score. In the third method, we apply a square root curve, where we find the square root of each score, and multiply it by 10.
Right now, it's difficult to understand what this code is for and looks pretty repetitive. This is an example of spaghetti code.
Let's use the tips we learned earlier on writing clean code and improve this with better naming and readable functions.
import math
import numpy as np
test_scores = [88, 92, 79, 93, 85]
print(np.mean(test_scores ))
curved_5 = [score + 5 for score in test_scores]
print(np.mean(curved_5))
curved_10 = [score + 10 for score in test_scores]
print(np.mean(curved_10))
curved_sqrt = [math.sqrt(score) * 10 for score in test_scores]
print(np.mean(curved_sqrt))
We can represent the list of scores better with something descriptive, like test_scores, and use numpy to get the mean of each list. We can also use list comprehensions to make this more concise and readable, and use more descriptive names for the score and resulting list. Our code is clear now, but still needs more refactoring.
First of all, the lines applying a flat curve of 5 and 10 look awfully similar. We can generalize this in one function and we can also consolidate all of these print statements into a for loop.
def flat_curve(arr, n):
return [i + n for i in arr]
def square_root_curve(arr):
return [math.sqrt(i) * 10 for i in test_scores]
test_scores = [88, 92, 79, 93, 85]
curved_5 = flat_curve(test_scores, 5)
curved_10 = flat_curve(test_scores, 10)
curved_sqrt = square_root_curve(test_scores)
for score_list in test_scores, curved_5, curved_10, curved_sqrt:
print(np.mean(score_list))
This actually demonstrates the next tip.
Notice how abstracting out code into a function not only makes it less repetitive, but also improves the readability with descriptive function names.
Note that although your code can become more readable when you abstract out logic into functions, it's possible to over-engineer this and have way too many functions. So, use your judgment.
There are trade-offs to having function calls instead of in-line logic.
If you've broken up your code into an unnecessary amount of functions and modules, you'll have to jump around everywhere. If you want to view the implementation details for something that may be too small to be worth it, it's kind of the same as naming variables.
A longer variable name doesn't necessarily equate to increased readability, the same way creating more modules doesn't necessarily result in effective modularization.
for example you wouldn't want something like this,
def flat_curve(arr, n):
curved_arr = [i + n for i in arr]
print(np.mean(curved_arr))
return curved_arr
def square_root_curve(arr):
curved_arr = [math.sqrt(i) * 10 for i in arr]
print(np.mean(curved_arr))
return curved_arr
test_scores = [88, 92, 79, 93, 85]
curved_5 = flat_curve(test_scores, 5)
curved_10 = flat_curve(test_scores, 10)
curved_sqrt = square_root_curve(test_scores)
This is the same thing we had before except now each curve function also prints the mean in addition to returning the adjusted list.
Avoid having unnecessary side effects and functions and keep them focused. Even if you rename them this way to indicate that they're printing the mean,
def flat_curve_and_print_mean(arr, n):
curved_arr = [i + n for i in arr]
print(np.mean(curved_arr))
return curved_arr
def square_root_curve_and_print_mean(arr):
curved_sqrt = [math.sqrt(i) * 10 for i in arr]
print(np.mean(curved_sqrt))
return curved_sqrt
test_scores = [88, 92, 79, 93, 85]
curved_5 = flat_curve(test_scores, 5)
curved_10 = flat_curve(test_scores, 10)
curved_sqrt = square_root_curve(test_scores)
The functions are still doing multiple things and become more difficult to generalize and reuse. Generally, if there's an and in your function name, consider refactoring.
def flat_curve(arr, n):
return [i + n for i in arr]
def square_root_curve(arr):
return [math.sqrt(i) * 10 for i in test_scores]
test_scores = [88, 92, 79, 93, 85]
curved_5 = flat_curve(test_scores, 5)
curved_10 = flat_curve(test_scores, 10)
curved_sqrt = square_root_curve(test_scores)
for score_list in test_scores, curved_5, curved_10, curved_sqrt:
print(np.mean(score_list))
Notice that in these functions, we broke some rules on using descriptive variable names (using arr as argument). This is because arbitrary variable names in general functions can actually make the code more readable. Flat curve doesn't actually have to be for test scores, it can be used on any iterable that you want to curve up by a certain integer.
Of course, there are times it's more appropriate to use many parameters, but in the vast majority of cases, it's more effective to use fewer arguments. Remember, we are modularizing to simplify our code and make it more efficient to work with. If your function has a lot of parameters, you may want to rethink how you're splitting this up.
Knowing how to write code that runs efficiently is another essential skill in software development. Optimizing code to be more efficient can mean making it:
The project on which you're working determines which of these is more important to optimize for your company or product. When you're performing lots of different transformations on large amounts of data, this can make orders of magnitudes of difference in performance.
Most programming languages have a set of capitalization rules that are used to ensure code is consistently styled and easy to read. These rules are sometimes called casing rules and are part of a system of naming conventions which are standards that developers follow in order to make sure their code is consistent with best practices and with the code of other developers. The most common casing rules include:
In some languages you may see variations of these as well as other conventions entirely. For example, it's common in Django settings files to use CAPS_LOCK_SNAKE_CASE for variable names to indicate that they represent an application setting, and CONSTANTS are sometimes capitalized in JavaScript to indicate that they shouldn't change.
The debate over whether to use tabs or spaces for indentation in coding is an old one. In fact, it dates back more than twenty years! The primary question to be answered is when indenting my code, should I use tabs or spaces?
This might seem like a silly debate, but it's actually significant. Most code editors today allow you to adjust the tab width, for example, from two to four spaces or more.
This can make code with a two-space indentation width like this:
<html>
<head>
<title></title>
</head>
<body>
<main class="main-content">
<h1>This is my website!</h1>
</main>
</body>
</html>
...look like this code, which uses four spaces for each new indentation level:
<html>
<head>
<title></title>
</head>
<body>
<main class="main-content">
<h1>This is my website!</h1>
</main>
</body>
</html>
The theory behind using spaces rather than tabs is that spaces always have a consistent width. They are always the same width on every operating system, every application and every code editor. This makes the code uniform no matter who is looking at it or which application they're using, and is the main reason people argue that it should be considered the best practice.
Proponents of using tabs to indent argue that the power of how to view the code should be left in the hands of the viewer, that is, if you use tabs it allows the reader of the code to adjust the tab width in their editor and view the code as it's easiest for them to read.
We recommend that you use spaces because from a computing standpoint it keeps your code consistent. You can still map your tab key in your editor to replace a tab with two or four spaces (most editors do this automatically these days anyway), but when it comes to the computer interpreting the code and maintaining consistency, it's best to use an indentation scheme that maintains a consistent width across all platforms. If the reader wants to adjust the tab width, it's still possible even if you use spaces in your code, because their editor will allow them to replace all spaces with tabs and then adjust it themselves if they feel it's necessary.
No matter what, one thing that all developers agree on is that you should never mix tabs and spaces together, since this can throw off the indentation entirely and in languages such as Python which depend on the indentation for execution, it will actually break the code.
Docstring, or documentation strings, are valuable pieces of documentation that explain the functionality of any function or module in your code. Ideally, each of your functions should always have a docstring.
Docstrings are surrounded by triple quotes. The first line of the docstring is a brief explanation of the function's purpose.
def population_density(population, land_area):
"""Calculate the population density of an area."""
return population / land_area
If you think that the function is complicated enough to warrant a longer description, you can add a more thorough paragraph after the one-line summary.
def population_density(population, land_area):
"""Calculate the population density of an area.
Args:
population: int. The population of the area
land_area: int or float. This function is unit-agnostic,
if you pass in values in terms of square km or square miles
the function will return a density in those units.
Returns:
population_density: population/land_area. The population density of a
particular area.
"""
return population / land_area
The next element of a docstring is an explanation of the function's arguments. Here, you list the arguments, state their purpose, and state what types the arguments should be. Finally, it is common to provide some description of the output of the function. Every piece of the docstring is optional; however, doc strings are a part of good coding practice.
Project documentation is essential for getting others to understand why and how your code is relevant to them, whether they are potential users of your project or developers who may contribute to your code. A great first step in project documentation is your README file. It will often be the first interaction most users will have with your project.
Whether it's an application or a package, your project should absolutely come with a README file. At a minimum, this should explain what it does, list its dependencies, and provide sufficiently detailed instructions on how to use it. Make it as simple as possible for others to understand the purpose of your project and quickly get something working.
Translating all your ideas and thoughts formally on paper can be a little difficult, but you'll get better over time, and doing so makes a significant difference in helping others realize the value of your project. Writing this documentation can also help you improve the design of your code, as you're forced to think through your design decisions more thoroughly. It also helps future contributors to follow your original intentions.
There is a full Udacity course on this topic.
Here are a few READMEs from some popular projects:
Testing your code is essential before deployment. It helps you catch errors and faulty conclusions before they make any major impact. Today, employers are looking for data scientists with the skills to properly prepare their code for an industry setting, which includes testing their code.
We want to test our functions in a way that is repeatable and automated. Ideally, we'd run a test program that runs all our unit tests and cleanly lets us know which ones failed and which ones succeeded. Fortunately, there are great tools available in Python that we can use to create effective unit tests!
The advantage of unit tests is that they are isolated from the rest of your program, and thus, no dependencies are involved. They don't require access to databases, APIs, or other external sources of information. However, passing unit tests isn’t always enough to prove that our program is working successfully. To show that all the parts of our program work with each other properly, communicating and transferring data between them correctly, we use integration tests. In this lesson, we'll focus on unit tests; however, when you start building larger programs, you will want to use integration tests as well.
To install pytest, run pip install -U pytest in your terminal. You can see more information on getting started here.
test_ is the default prefix - if you wish to change this, you can learn how to in this pytest configuration
In the test output, periods represent successful unit tests and F's represent failed unit tests. Since all you see is what test functions failed, it's wise to have only one assert statement per test. Otherwise, you wouldn't know exactly how many tests failed, and which tests failed.
Your tests won't be stopped by failed assert statements, but it will stop if you have syntax errors.
compute_launch.py
def days_until_launch(current_day, launch_day):
""""Returns the days left before launch.
current_day (int) - current day in integer
launch_day (int) - launch day in integer
"""
return launch_day - current_day if launch_day > current_day else 0
*-----------------------------------------------------------------------------------------------------------------------------*
test_compute_launch.py
from compute_launch import days_until_launch
def test_days_until_launch_4():
assert(days_until_launch(22, 26) == 4)
def test_days_until_launch_0():
assert(days_until_launch(253, 253) == 0)
def test_days_until_launch_0_negative():
assert(days_until_launch(83, 64) == 0)
def test_days_until_launch_1():
assert(days_until_launch(9, 10) == 1)
*-----------------------------------------------------------------------------------------------------------------------------*
in terminal:
ruszki@DESKTOP MINGW64 ~/CodingPractices
$ pytest
================================= test session starts =====================================
platform win32 -- Python 3.8.5, pytest-6.2.4, py-1.9.0, pluggy-0.13.1
rootdir: C:\Users\ruszk\Google Drive\Learning\CodingPractices
collected 4 items
test_compute-launch.py ..F. [100%]
==================================== FAILURES =============================================
________________________ test_days_until_launch_0_negative ________________________________
def test_days_until_launch_0_negative():
> assert(days_until_launch(83, 64) == 0)
E assert -19 == 0
E + where -19 = days_until_launch(83, 64)
test_compute-launch.py:10: AssertionError
================================= warnings summary =======================================
..\..\..\..\..\programdata\anaconda3\lib\site-packages\pyreadline\py3k_compat.py:8
c:\programdata\anaconda3\lib\site-packages\pyreadline\py3k_compat.py:8: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
return isinstance(x, collections.Callable)
-- Docs: https://docs.pytest.org/en/stable/warnings.html
============================ short test summary info =====================================
FAILED test_compute-launch.py::test_days_until_launch_0_negative - assert -19 == 0
======================== 1 failed, 3 passed, 1 warning in 0.45s ==========================
ruszki@DESKTOP MINGW64 ~/CodingPractices
$ pytest
=========================== test session starts ==========================================
platform win32 -- Python 3.8.5, pytest-6.2.4, py-1.9.0, pluggy-0.13.1
rootdir: C:\Users\ruszk\Google Drive\Learning\CodingPractices
collected 4 items
test_compute-launch.py .... [100%]
========================= 4 passed in 0.11s ==============================================
Test-driven development for data science is relatively new and is experiencing a lot of experimentation and breakthroughs. You can learn more about it by exploring the following resources.
Integration testing exercises two or more parts of an application at once, including the interactions between the parts, to determine if they function as intended. This type of testing identifies defects in the interfaces between disparate parts of a codebase as they invoke each other and pass data between themselves.
While unit testing is used to find bugs in individual functions, integration testing tests the system as a whole. These two approaches should be used together, instead of doing just one approach over the other. When a system is comprehensively unit tested, it makes integration testing far easier because many of the bugs in the individual components will have already been found and fixed.
As a codebase scales up, both unit and integration testing allow developers to quickly identify breaking changes in their code. Many times these breaking changes are unintended and wouldn't be known about until later in the development cycle, potentially when an end user discovers the issue while using the software. Automated unit and integration tests greatly increase the likelihood that bugs will be found as soon as possible during development so they can be addressed immediately.
Logging is valuable for understanding the events that occur while running your program. For example, if you run your model overnight and see that it's producing ridiculous results the next day, log messages can really help you understand more about the context in which this occurred. Lets learn about the qualities that make a log message effective.
Logging is the process of recording messages to describe events that have occurred while running your software. Let's take a look at a few examples, and learn tips for writing good log messages.
Bad: Hmmm... this isn't working???
Bad: idk.... :(
Good: Couldn't parse file.
Bad: Start Product Recommendation Process
Bad: We have completed the steps necessary and will now proceed with the recommendation process for the records in our product database.
Good: Generating product recommendations.
DEBUG - level you would use for anything that happens in the program.
ERROR - level to record any error that occurs
INFO - level to record all actions that are user-driven or system specific, such as regularly scheduled operations
Bad: Failed to read location data
Good: Failed to read location data: store_id 8324971
ERROR - Failed to compute product similarity. I made sure to fix the error from October so not sure why this would occur again.
ERROR is the appropriate level for this error message, though more information on where, when, how, etc. this occurred would be useful for debugging. It's best practice to use concise and clear language that is professional and uses normal capitalization. This way, the message is efficient and easily understandable. The second sentence seems quite unclear and personal, so we should remove that and communicate it elsewhere.
Code reviews benefit everyone in a team to promote best programming practices and prepare code for production.
Code reviews are a key part of the development process. We do them for every change. They are a form of asynchronous pair programming and they should hopefully help us spot bugs and design mistakes in our code before our users do.
Doing reviews for other people's code is an essential part of every developer's job. It is one of the highest priority things you can work on. Every open pull request we have is a change that isn't shipping to users. Since we often need multiple attempts at a new feature to get it just right for our users that means the longer reviews take the longer it takes us to get polished features completed. However, code reviews start with a pull request, and that means you have a responsibility to make people actually want to review your code when you make one.
Benefits:
You should read over your own code before you create the pull request (PR). Do a git add for the affected files / directories and then run a git diff --staged to examine the changes you have not yet committed. Usually look for things like:
You want to make sure that it would pass your own code review first before you subject other people to it. It also stings less to get notes from yourself than from others.
Small changes are much easier to review. They're also much easier to explain to people. This means that mistakes are less likely to sneak through and the discussion of the change should be much more productive. It also means your PR should avoid ending up with tens of comments that go round and round in circles without ever getting your code merged. It is not always possible to break a change up into small parts but it very often is. A good guideline for this is that your change should not affect a combined total of more than 400 lines.
The title of the PR should include the reference for any tickets covered by this change. You may also want to copy the description from the ticket into your description. The description for your PR should tell the story of your change in a clear and concise way. It should explain both why you are making this change and what you changed. Not all reviewers will have a deep knowledge of that part of the system so you must make it possible for them to provide useful insight. This means explaining what the existing behaviour was, how you changed it, and why this was thought to be useful.
Your commits should be logically separate changes. This means that you should aim to separate things like lint cleanups from actual behaviour changes. They should have good commit messages that explain what was changed at each step.
You shouldn't go off and get stuck into something else while you have PRs open. This makes the reviews less effective for everyone because everyone will now need to switch context more frequently. You will need to remember what was going on in your change, they will need to familiarise themselves with what was going on when they raised a comment. If you have a PR open your number 1 priority should be getting it reviewed and merged.
If you're working on a component or a service that others are not familiar with then offer to do an in-person pair review with someone. This guarantees you'll get eyes on your changes and get your code through the door quicker. It's also a great way for knowledge sharing and teaching people new techniques.
The primary purpose of code review is to make sure that the overall code health of the code base is improving over time. In order to accomplish this, a series of trade-offs have to be balanced.
First, developers must be able to make progress on their tasks. If you never submit an improvement to the codebase, then the codebase never improves. Also, if a reviewer makes it very difficult for any change to go in, then developers are disincentivized to make improvements in the future.
On the other hand, it is the duty of the reviewer to make sure that each CL is of such a quality that the overall code health of their codebase is not decreasing as time goes on. This can be tricky, because often, codebases degrade through small decreases in code health over time, especially when a team is under significant time constraints and they feel that they have to take shortcuts in order to accomplish their goals.
Also, a reviewer has ownership and responsibility over the code they are reviewing. They want to ensure that the codebase stays consistent, maintainable, and all of the other things mentioned in “What to look for in a code review.”
Thus, we get the following rule as the standard we expect in code reviews:
In general, reviewers should favor approving a CL once it is in a state where it definitely improves the overall code health of the system being worked on, even if the CL isn’t perfect.
That is the senior principle among all of the code review guidelines.
There are limitations to this, of course. For example, if a CL adds a feature that the reviewer doesn’t want in their system, then the reviewer can certainly deny approval even if the code is well-designed.
A key point here is that there is no such thing as “perfect” code—there is only better code. Reviewers should not require the author to polish every tiny piece of a CL before granting approval. Rather, the reviewer should balance out the need to make forward progress compared to the importance of the changes they are suggesting. Instead of seeking perfection, what a reviewer should seek is continuous improvement. A CL that, as a whole, improves the maintainability, readability, and understandability of the system shouldn’t be delayed for days or weeks because it isn’t “perfect.”
Reviewers should always feel free to leave comments expressing that something could be better, but if it’s not very important, prefix it with something like “Nit: “ to let the author know that it’s just a point of polish that they could choose to ignore.
Note: Nothing in this document justifies checking in CLs that definitely worsen the overall code health of the system. The only time you would do that would be in an emergency.
Code review can have an important function of teaching developers something new about a language, a framework, or general software design principles. It’s always fine to leave comments that help a developer learn something new. Sharing knowledge is part of improving the code health of a system over time. Just keep in mind that if your comment is purely educational, but not critical to meeting the standards described in this document, prefix it with “Nit: “ (short for nit-picking) or otherwise indicate that it’s not mandatory for the author to resolve it in this CL.
Because getting PRs merged quickly is so important you need to stay on top of the changes people want your input on. You can use tools like Trailer.app or even simply search in GitHub using "involves:<YOUR USERNAME>" to find PRs relevant to you.
Tolerate being interrupt driven. You need focussed time to get your other work done but PRs are time sensitive because they block other people. You shouldn't put off code review for more than a few hours. Never more than a day.
It's one of the most important things you can work on. The only things that should come ahead of it are time critical work such as fixing availability problems or dealing with high priority requests from customers. This means you should expect to spend some time every day doing reviews and that you will probably need to spend 2-3 sessions per day replying to PRs and reading other people's code.
Reviewing code is hard and error prone. It is our last line of defence against downtime and tech debt. You must pay attention, ask questions and not +1 lightly. Sometimes you will slip and miss something or only notice late in the review process. This is not great but it is forgiven. Own up to it and move on. Confused about a bit of code? Ask what it does - there are no stupid questions.
While code reviews need to be done thoughtfully and thoroughly we also need to avoid blocking progress. This means you should help people with solutions, not only identify problems. Be aware that some test suites take some time to run and it may make more sense for some fixes to be made in subsequent PRs instead of being added to this one. Don’t let a CL sit around because the author and the reviewer can’t come to an agreement.
In any conflict on a code review, the first step should always be for the developer and reviewer to try to come to consensus, based on the contents of this document and the other documents in The CL Author’s Guide and this Reviewer Guide.
When coming to consensus becomes especially difficult, it can help to have a face-to-face meeting or a video conference between the reviewer and the author, instead of just trying to resolve the conflict through code review comments. (If you do this, though, make sure to record the results of the discussion as a comment on the CL, for future readers.)
If that doesn’t resolve the situation, the most common way to resolve it would be to escalate. Often the escalation path is to a broader team discussion, having a Technical Lead weigh in, asking for a decision from a maintainer of the code, or asking an Eng Manager to help out.
Let's go over what to look for in a code review and some tips on how to conduct one.
Now that we know what we are looking for, let's go over some tips on how to actually write your code review. When your coworker finishes up some code that they want to merge to the team's code base, they might send it to you for review. You provide feedback and suggestions, and then they may make changes and send it back to you. When you are happy with the code, you approve and it gets merged to the team's code base.
As you may have noticed, with code reviews you are now dealing with people, not just computers. So it's important to be thoughtful of their ideas and efforts. You are in a team and there will be differences in preferences. The goal of code review isn't to make all code follow your personal preferences, but a standard of quality for the whole team.
This isn't really a tip for code review, but can save you lots of time from code review! Using a Python code linter like pylint can automatically check for coding standards and PEP 8 guidelines for you! It's also a good idea to agree on a style guide as a team to handle disagreements on code style, whether that's an existing style guide or one you create together incrementally as a team.
Rather than commanding people to change their code a specific way because it's better, it will go a long way to explain to them the consequences of the current code and suggest changes to improve it. They will be much more receptive to your feedback if they understand your thought process and are accepting recommendations, rather than following commands. They also may have done it a certain way intentionally, and framing it as a suggestion promotes a constructive discussion, rather than opposition.
BAD: Make model evaluation code its own module - too repetitive.
BETTER: Make the model evaluation code its own module. This will simplify models.py to be less repetitive and focus primarily on building models.
GOOD: How about we consider making the model evaluation code its own module? This would simplify models.py to only include code for building models. Organizing these evaluation methods into separate functions would also allow us to reuse them with different models without repeating code.
Try to avoid using the words "I" and "you" in your comments. You want to avoid comments that sound personal to bring the attention of the review to the code and not to themselves.
BAD: I wouldn't groupby genre twice like you did here... Just compute it once and use that for your aggregations.
BAD: You create this groupby dataframe twice here. Just compute it once, save it as groupby_genre and then use that to get your average prices and views.
GOOD: Can we group by genre at the beginning of the function and then save that as a groupby object? We could then reference that object to get the average prices and views without computing groupby twice.
When providing a code review, you can save the author time and make it easy for them to act on your feedback by writing out your code suggestions. This shows you are willing to spend some extra time to review their code and help them out. It can also just be much quicker for you to demonstrate concepts through code rather than explanations.
Let's say you were reviewing code that included the following lines:
first_names = []
last_names = []
for name in enumerate(df.name):
first, last = name.split(' ')
first_names.append(first)
last_names.append(last)
df['first_name'] = first_names
df['last_names'] = last_names
BAD: You can do this all in one step by using the pandas str.split method.
GOOD: We can actually simplify this step to the line below using the pandas str.split method. Found this on this stack overflow post: https://stackoverflow.com/questions/14745022/how-to-split-a-column-into-two-columns
df['first_name'], df['last_name'] = df['name'].str.split(' ', 1).str
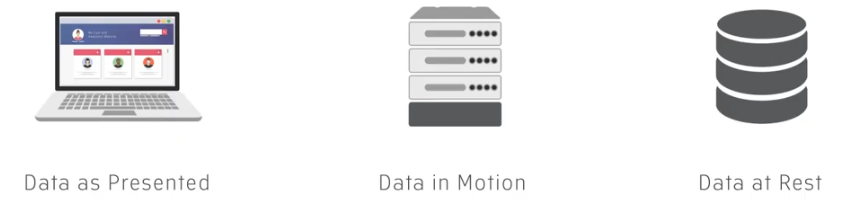
"data as presented" is what the end-user sees when they view an application,
"data in motion" is the data that is used within the processes and algorithms that determine how an application works,
"data at rest" is data that is stored on, and accessed from, files and disks for use by applications.